
Individual tools, services and demos
uRank – an interactive web-based tool that supports interest-driven browsing and re-ranking of search results. uRank is an interactive web-based tool implemented in the MOVING platform, that supports interest-driven browsing and re-ranking of search results. The approach combines lightweight text analytics and a stacked bar chart visualization to convey a content-based ranking of documents in a search result set. The key of this approach lies in its dynamic nature, supported by a user-driven method for updating the ranking visualization that allows users to refine their search interest as it evolves during exploration. The documents and their keywords are passed to the uRank user interface, which consists of three main components: i) The Tag Box, which offers a summary of the document collection by representing extracted key-words as tags. ii) The Query Box, which is a container where the user adds keywords of particular interest. iii) The Document List, which shows the hits sorted according to the user-selected keywords. Each hit includes the document title, its ranking position information, the positional “shift” of the document, indicating how much a document changed its ranking since the last action, and a stacked bar chart depicting relevance scores in terms of user-selected keywords (i.e. keywords in the Query Box). Changes in the ranking representation originate from manipulating keyword tags within the Query Box in three different ways: i) addition by clicking on the tags in the Tag Box, ii) weight tuning through keyword-sliders, and iii) deletion. As the user selects terms of interest, the ranking visualization brings related documents to the top and pushes down less relevant ones. An older implemented version of the tool can be seen under https://github.com/cecidisi/uRank.
Please find more information in our short video tutorial below.
LODatio+ – Searching the Content of the Web of Data. LODatio+ is a search engine to locate data sources in the Web of Data that contain resources of specific types and using specific properties. For a given information need, LODatio+ returns not only the matching data sources but also provides query recommendations to generalize or to narrow down the information need. Users can formulate their information need as a SPARQL query using only types and properties. The example queries provided can help users get familiar with these queries. For each query, LODatio+ provides a ranked list of data sources in the Web of Data that contain data matching the types and properties specified in the query.
LODatio+ is running as part of the MOVING platform. It is maintained by ZBW – Leibniz information center for economics in Kiel. Based on LODatio+, we developed the Data Integration Service for the Web of Data. With LODatio+, we first find data with certain attributes, for example, bibliographic metadata with title, authors, concepts or keywords, an abstract, and a link to the full-text. This helps us to enhance the scientific content available over the MOVING platform by including this freely available, linked open metadata provided by various data sources. First, we discover data sources with LODatio+ providing bibliographic metadata. Then, we access the data sources, retrieve the appropriate metadata, automatically convert it into our internal data format, and integrate it in the MOVING platform. For MOVING, we focused on bibliographic metadata. However, LODatio+, as well as the Data Integration Service, are designed to find, harvest, and convert any kind of data on the Web.
Please find more information in our short video tutorial below or try the public prototype directly.
WevQuery – A scalable system for testing hypotheses about web interaction patterns. Remotely stored user interaction logs give access to a wealth of data generated by large numbers of users which can be used to understand if interactive systems meet the expectations of designers. Unfortunately, detailed insight into users’ interaction behaviour still requires a high degree of expertise. WevQuery allows designers to test their hypotheses about users’ behaviour by using a graphical notation to define the interaction patterns designers are seeking. WevQuery is scalable as the queries can then be executed against large user interaction datasets by employing the MapReduce paradigm. This way WevQuery provides designers effortless access to harvest users’ interaction patterns, removing the burden of low-level interaction data analysis. You can find more information regarding the system and download it under: https://github.com/aapaolaza/WevQuery
SciFiS – A Search Engine for Scientific Figures.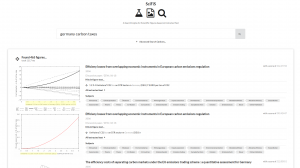 Scientific figures like bar charts, pie charts, maps, scatter plots, or similar infographics often include valuable textual information, which is not present in the surrounding text. A new tool developed by the ZBW Knowledge Discovery Research Group enables the search in such infographics and thus offers new ways to access publications. A public prototype allows the search for infographics in open access publications taken from EconBiz. The prototype can be accessed at http://broca.informatik.uni-kiel.de:20080/ and more information about this research can be found at http://www.kd.informatik.uni-kiel.de/en/research/software/text-extraction.
Scientific figures like bar charts, pie charts, maps, scatter plots, or similar infographics often include valuable textual information, which is not present in the surrounding text. A new tool developed by the ZBW Knowledge Discovery Research Group enables the search in such infographics and thus offers new ways to access publications. A public prototype allows the search for infographics in open access publications taken from EconBiz. The prototype can be accessed at http://broca.informatik.uni-kiel.de:20080/ and more information about this research can be found at http://www.kd.informatik.uni-kiel.de/en/research/software/text-extraction.
Interactive online demo with audio and video analysis results in lecture and non-lecture videos. CERTH released an interactive online demo linking lecture videos, using general purpose concepts that were produced from textual analysis of their transcripts, with non-lecture videos, using their visual analysis results such as automatically detected shots, scenes, and visual concepts. You can access the demo at: http://multimedia2.iti.gr/moving-project/lecture-video-linking-demo/results.html (best viewed with Firefox).
Scientific Paper Recommendation using Sparse Title Data. The system delivers recommended scientific papers in economics based on what a social media user tweeted. It profiles papers as well as tweets using our novel method HCF-IDF (Hierarchical Concept Frequency Inverse Document Frequency). HCF-IDF extracts semantic concepts from texts and applies spreading activation based on a hierarchical thesaurus, which is freely available in many different domains. Spreading activation enables to extract relevant semantic concepts which are not mentioned in texts and mitigates shortness and sparseness of texts. The novel method HCF-IDF demonstrated the best performance in a larger user experiment published at JCDL’16. In this demo, you may compare the two different configurations, HCF-IDF using only titles of papers and HCF-IDF using both titles and full-texts of papers. Different from the traditional methods, HCF-IDF can provide competitive recommendations already using only titles.
http://amygdala.informatik.uni-kiel.de/Demo/TwitterAccount
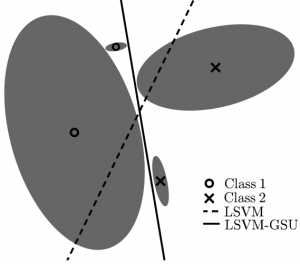 Support Vector Machine with Gaussian Sample Uncertainty (SVM-GSU). SVM-GSU is a maximum margin classifier that deals with uncertainty in data input. More specifically, the SVM framework is reformulated such that each training example can be modeled by a multi-dimensional Gaussian distribution described by its mean vector and its covariance matrix – the latter modeling the uncertainty. We address the classification problem and define a cost function that is the expected value of the classical SVM cost when data samples are drawn from the multi-dimensional Gaussian distributions that form the set of the training examples. Our formulation approximates the classical SVM formulation when the training examples are isotropic Gaussians with variance tending to zero. We arrive at a convex optimization problem, which we solve efficiently in the primal form using a stochastic gradient descent approach. The resulting classifier, which we name SVM with Gaussian Sample Uncertainty (SVM-GSU), is tested on synthetic data and five publicly available and popular datasets; namely, the MNIST, WDBC, DEAP, TV News Channel Commercial Detection, and TRECVID MED datasets. Experimental results verify the effectiveness of the proposed method.
Support Vector Machine with Gaussian Sample Uncertainty (SVM-GSU). SVM-GSU is a maximum margin classifier that deals with uncertainty in data input. More specifically, the SVM framework is reformulated such that each training example can be modeled by a multi-dimensional Gaussian distribution described by its mean vector and its covariance matrix – the latter modeling the uncertainty. We address the classification problem and define a cost function that is the expected value of the classical SVM cost when data samples are drawn from the multi-dimensional Gaussian distributions that form the set of the training examples. Our formulation approximates the classical SVM formulation when the training examples are isotropic Gaussians with variance tending to zero. We arrive at a convex optimization problem, which we solve efficiently in the primal form using a stochastic gradient descent approach. The resulting classifier, which we name SVM with Gaussian Sample Uncertainty (SVM-GSU), is tested on synthetic data and five publicly available and popular datasets; namely, the MNIST, WDBC, DEAP, TV News Channel Commercial Detection, and TRECVID MED datasets. Experimental results verify the effectiveness of the proposed method.
Reference:
Tzelepis, V. Mezaris, I. Patras, “Linear Maximum Margin Classifier for Learning from Uncertain Data”, IEEE Transactions on Pattern Analysis and Machine Intelligence, accepted for publication. DOI:10.1109/TPAMI.2017.2772235. An alternate preprint version is available here.
Code available at: https://github.com/chi0tzp/svm-gsu
FluID. Finding data sources containing relevant information on the web for a given information need is crucial to the success of the LinkedOpen Data (LOD) idea. However, this is a challenging task since there is a vast amount of data available, which is distributed over various data sources. Schema-level indices allow finding data sources for topological queries using patterns of RDF types and properties. The FLuID (short for: Flexible schema-Level Index model for the web of Data) framework was developed to compute and query arbitrary schema-level indices. Further information is available in deliverable D3.2: Technologies for MOVING data processing and visualisation v2.0, Section 3.2. The source code of the FLuID framework is published under an open source license in GitHub.
Code available at: https://github.com/t-blume/fluid-framework
IMPULSE. The Bibliographic Metadata Injection Service accesses data sources, retrieves the appropriate metadata, and automatically converts it into our internal data format. The IMPULSE (short for: Integrate Public Metadata Underneath professional Library SErvices) framework was developed to realise the Bibliographic Metadata Injection Service. The source code is published under an open source license on GitHub. An exhaustive description of the Bibliographic Metadata Injection Service is provided in deliverable D4.3: Final responsive platform prototype, modules and common communication protocol, Section 7.1.3. The results of the experimental evaluation conducted with IMPULSE are available in Zenodo.
Experimental results available at: https://zenodo.org/record/2553811#.XK5D1aRS9EY, and code available at: https://github.com/t-blume/impulse
Automatic semantic document annotation. Document annotation is the process of assigning subject labels to documents to later effectively retrieve them. We investigated to what extent automated semantic document annotation can be conducted with only using the titles of documents instead of the full-text, as described in deliverable D3.2: Technologies for MOVING data processing and visualisation v2.0, Section 3.7 and deliverable D3.3: Technologies for MOVING data processing and visualisation v3.0, Section 3.6. This is an important feature as often only document’s titles are available. We adapted multiple traditional as well as modern multi-label classification approaches to operate only on the title of the documents. To exploit the large amounts of data available in the MOVING platform to their full potential, we developed three strong deep learning classifiers. The source code is published under an open source license in GitHub.
Code available at: https://github.com/Quadflor/quadflor, https://github.com/florianmai/Quadflor
Semantic profiling and recommender system. An enormous volume of scientific content is published every year. The amount exceeds by far what a scientist can read in her entire life. In order to address this problem, the MOVING platform is equipped with a recommender system. In our MOVING recommender system, we improved on the previous work experimenting advanced techniques based on deep learning to recommend papers or subject labels to assign to them. These techniques are extensively described in deliverable D3.2: Technologies for MOVING data processing and visualisation v2.0, Section 6. The source code used is openly available in Github.
Code available at: https://github.com/lgalke/aae-recommender
Elastify. While there are many studies on information retrieval models using full-text, there are presently no comparison studies of full-text retrieval vs. retrieval only over the titles of documents. On the one hand, the full-text of documents like scientific papers is not always available due to, e. g., copyright policies of academic publishers. On the other hand, conducting a search based on titles alone has strong limitations. Titles are short and therefore may not contain enough information to yield satisfactory search results. We compared different retrieval models regarding their search performance on the full-text vs. only titles of documents. These models are extensively described in deliverable D3.2: Technologies for MOVING data processing and visualisation v2.0, Section 3.6. The source code is published under an open source license in bitbucket.
Code available at: https://bitbucket.org/elastify/elastify
Related tools and demos by the MOVING partners
Text Extraction from Scholarly Figures. Scholarly figures are data or visualizations like bar charts, pie charts, line graphs, maps, scatter plots or similar figures. Text extraction from scholarly figures is useful in many application scenarios, since text in scholarly figures often contains information that is not present in the surrounding text. We derived a generic pipeline for text extraction from the analysis of the wide research area on text extraction from figures and implemented in total over 20 methods for the six sequential steps of the pipeline.
http://www.kd.informatik.uni-kiel.de/en/research/software/text-extraction
![]() Interactive on-line video analysis service lets you upload videos via a web interface, and it performs shot/scene segmentation and visual concept detection (several times faster than real-time; uses our new concept detection engine). Results are displayed in an interactive user interface, which allows navigating through the video structure (shots, scenes), viewing the concept detection results for each shot, and searching by concepts within the video. Try this service now!
Interactive on-line video analysis service lets you upload videos via a web interface, and it performs shot/scene segmentation and visual concept detection (several times faster than real-time; uses our new concept detection engine). Results are displayed in an interactive user interface, which allows navigating through the video structure (shots, scenes), viewing the concept detection results for each shot, and searching by concepts within the video. Try this service now!